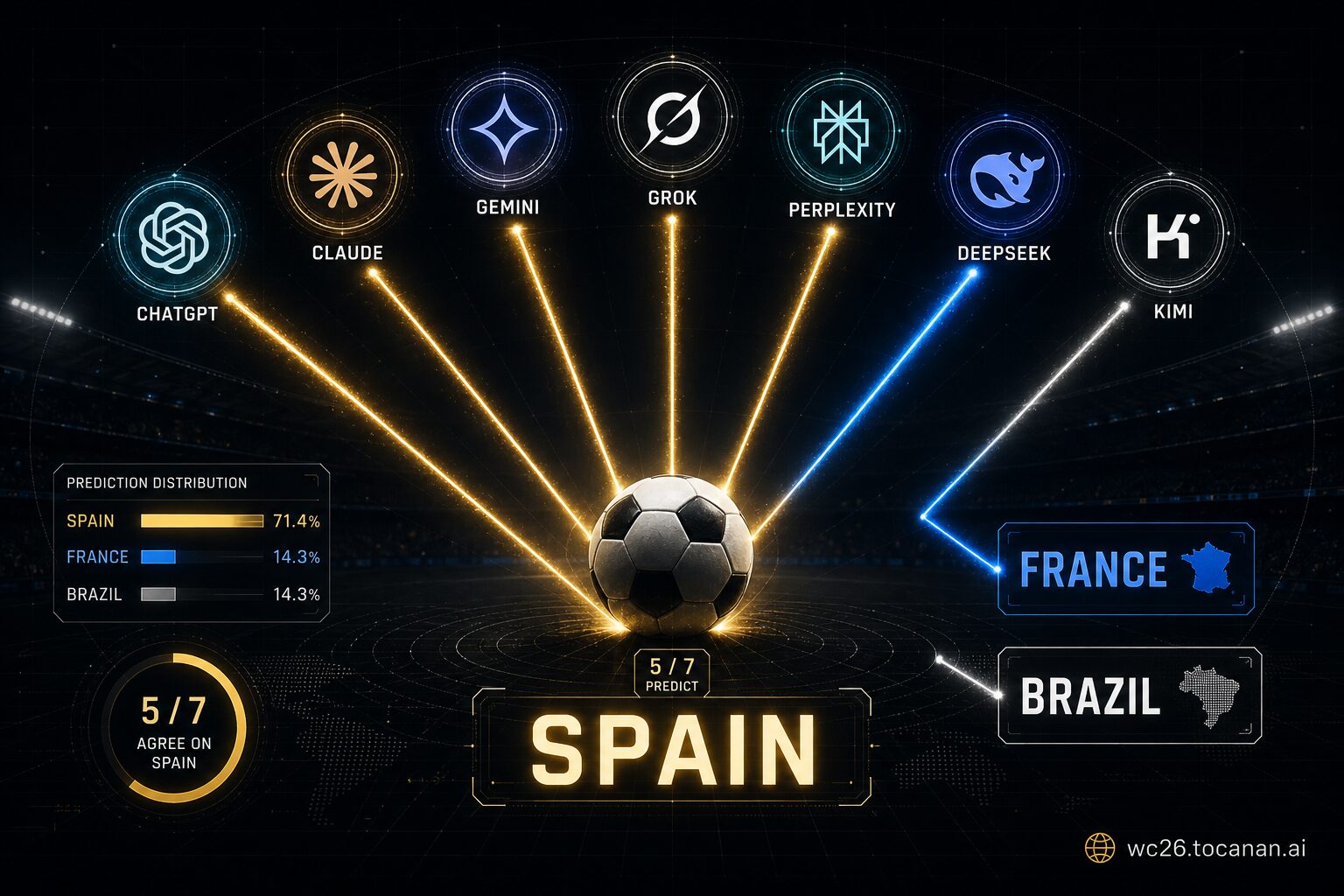
I asked seven AI platforms who’ll win the biggest football tournament of the summer. Five said Spain. One said France. One said Brazil. Same question, same day, same real-time data.
The average divergence across all our tracked questions is 58 out of 100 — where 0 means perfect agreement and 100 means total chaos.
That disagreement is the entire point.
The build
I’ve built a system that queries ChatGPT, Claude, Gemini, Grok, Perplexity, DeepSeek, and Kimi — each through its own real-time web search — so every model answers from today’s news, not last year’s training data. Their answers feed a consensus engine that doesn’t just count votes: it weighs each platform’s stated confidence against its trailing accuracy, so the ensemble learns who to trust as the tournament unfolds.
The integrity rules are strict — every prediction locks at kickoff. No model gets credit for “predicting” a result it could simply look up.
Everything goes on a public accuracy leaderboard at wc26.tocanan.ai, including the consensus itself, scored under the same rules as the individual platforms. The hypothesis, borrowed from decades of forecasting research: a well-weighted ensemble should beat its best member. By the final on July 19, we’ll know.
Full disclosure: the system was itself built with AI — specifically Anthropic’s Claude Fable 5 for the consensus weighting, integrity rules, and retrieval architecture.
Why a marketing person is doing forecasting science
Because the divergence is the story.
If seven AI platforms, given the same question on the same day, return different answers about a football match — what do you think they’re saying about your company?
We ran a similar exercise for a leading brand. ChatGPT recommended them by name. Gemini didn’t mention them at all. Same category, same query, two completely different realities. That brand had spent twenty years optimising for one search engine and was invisible across the new ones.
When a prospect asks ChatGPT “what’s the best [your category] tool?”, that answer is a prediction too. It’s assembled the same way: retrieval, weighting, synthesis. And it diverges across platforms just as wildly as the picks in that cover image. Most brands have never once checked.
That’s the discipline we work on at Tocanan.ai: GEO — generative engine optimisation. This tracker is the public proof that platform divergence is real, measurable, and consequential. The leaderboard isn’t a scoreboard; it’s evidence.
Follow the experiment
The machine runs daily, so the updates will too:
wc26.tocanan.ai — the live arena, updated daily: every prediction, the consensus, the divergence index, and the accuracy leaderboard as results come in. Bookmark it.
A weekly deep-dive every Monday: accuracy rankings, what the consensus engine learned, and what it means for how AI platforms talk about brands.
Both will carry the numbers exactly as they land — the hits and the misses, the leaderboard unedited. An experiment that hides its failures isn’t an experiment; it’s an ad.
And if you want to see what the seven oracles currently say about your brand, that audit takes five minutes: audit.tocanan.ai
Related reading
- Google AI Overview: How Citation Surfaces Work in 2026
- GEO Poisoning: Protecting Your Brand in AI Search
Frequently Asked Questions
What is AI prediction divergence?
AI prediction divergence measures how much different AI platforms disagree when asked the same question. Our tracker queries seven leading AI platforms daily and calculates a divergence index from 0 (perfect agreement) to 100 (total disagreement). The same divergence exists when AI platforms answer questions about brands, products, and services.
How does Generative Engine Optimization (GEO) work?
GEO is the practice of optimising how your brand appears in AI-generated answers across platforms like ChatGPT, Gemini, Perplexity, Claude, and others. Unlike traditional SEO which targets one search engine, GEO ensures your brand is visible, accurate, and recommended across all major AI platforms simultaneously.
Do AI platforms agree on football predictions?
No — our daily tracking shows an average divergence of 58/100 across seven AI platforms answering identical football prediction questions. Each platform retrieves different sources, weights information differently, and arrives at different conclusions. This same inconsistency applies to how AI platforms describe brands and recommend products.
About the Author
Eden Lau is CEO of Tocanan.ai, a GEO intelligence company that tracks how AI platforms represent brands across ChatGPT, Gemini, Perplexity, Claude, Grok, DeepSeek, and Kimi. With 30+ years in marketing data strategy, he previously co-founded Brandtology. Connect on LinkedIn.