Most AI prediction content is theatre.
It is a screenshot after the fact, a clever prompt, a dramatic claim, or a single answer treated as evidence. There is rarely a public timestamp, a scoring method, or accountability when reality arrives. I wanted to do the opposite.
For the World Cup 2026, I built a public AI-prediction experiment at wc26.tocanan.ai. Every match prediction is published before kickoff, scored against the result, and left untouched afterwards. The same question is asked across ChatGPT, Claude, Gemini, Grok, Perplexity, DeepSeek and Kimi.
Four versions in, the experiment has become more than a football project. It is a live demonstration of how I think AI judgment should be measured, improved and commercialised. That is why it matters for Generative Engine Optimization, or GEO.

The Experiment In Four Versions
AI judgment only becomes visible when the question, answer and scoring frame are disciplined enough to compare. That sounds obvious. In practice, it is where most AI evaluation breaks.
V1: Measurement Needs Standardisation
V1 was deliberately rough. The models were asked for free-form answers. They explained themselves in different shapes, used different levels of confidence, and sometimes embedded the verdict inside prose. That made the content interesting, but it made measurement fragile.
The lesson was simple: measurement infrastructure must come before insight. If the output is not standardised, comparability collapses. You have a pile of opinions, not a leaderboard.
For GEO, this matters immediately. A brand cannot meaningfully ask, “How visible are we in AI?” if every platform is tested with a different prompt, answer format and scoring rule.
V2: Model Personality Becomes Visible
V2 forced the models into one prediction format. That made the answers scorable, and exposed something more interesting: distribution bias.
The same question can produce very different default postures across models. Some are decisive. Some hedge. Some over-index on draws. Some avoid them.
Across match predictions, Kimi’s draw share is 32.5%, while Claude’s is 2.4%, a roughly 13x spread on the same task. That same platform-specific variance is why Chinese AI platforms need to be measured separately.
That is not a small stylistic difference. It is a measurable model personality. Decisive can be useful, but it can also hide weak reasoning. Caution can be balanced, but too much hedging dilutes actionability. V2 made one thing clear: you should never treat “the AI answer” as a single thing.
V3: Context Changes The Data
On 21 June 2026, I deployed the V3 cutover. I added structured probabilities and a risk field to the prompt and parser, moving the system from a bare verdict toward calibrated reasoning.
After the cutover, 728 predictions carry explicit probability breakdowns and 546 carry an explicit risk field, fields that did not exist before V3.
Better context improved the test without erasing model personality. Instead of only asking, “What did the model pick?”, V3 made it possible to ask:
- How confident was it?
- Did it recognise the draw risk?
- Did the probability distribution support the verdict?
That is the difference between a probability score and actionable intelligence. In GEO terms, it is the difference between knowing whether a brand appears and knowing why the model presented it that way.
V4: Destination Versus Route
V4 is the live next step. The current question is whether models distinguish the destination from the route.
The destination is the final answer: who advances, who wins, what the model thinks will happen. The route is how it happens: a 90-minute win, a regulation draw, extra time, penalties, or a late swing.
One match showed the value clearly. All seven models agreed on the winner, but split on the path. Five predicted a regulation draw, implying extra time or penalties, while ChatGPT and Perplexity backed a 90-minute win. Same verdict, different reading of the tension.
I am not claiming a measured V4 accuracy lift yet. The knockout leaderboard is not populated until knockout results land, and the V4-versus-V3 accuracy deltas will be folded in only when the data exists. The experiment only works if the rules are not rewritten after the fact.
What I can say now is qualitative: V4 makes the intelligence more decomposable. It separates “what will happen” from “how it will happen”. That is where AI output becomes useful.
By The Numbers
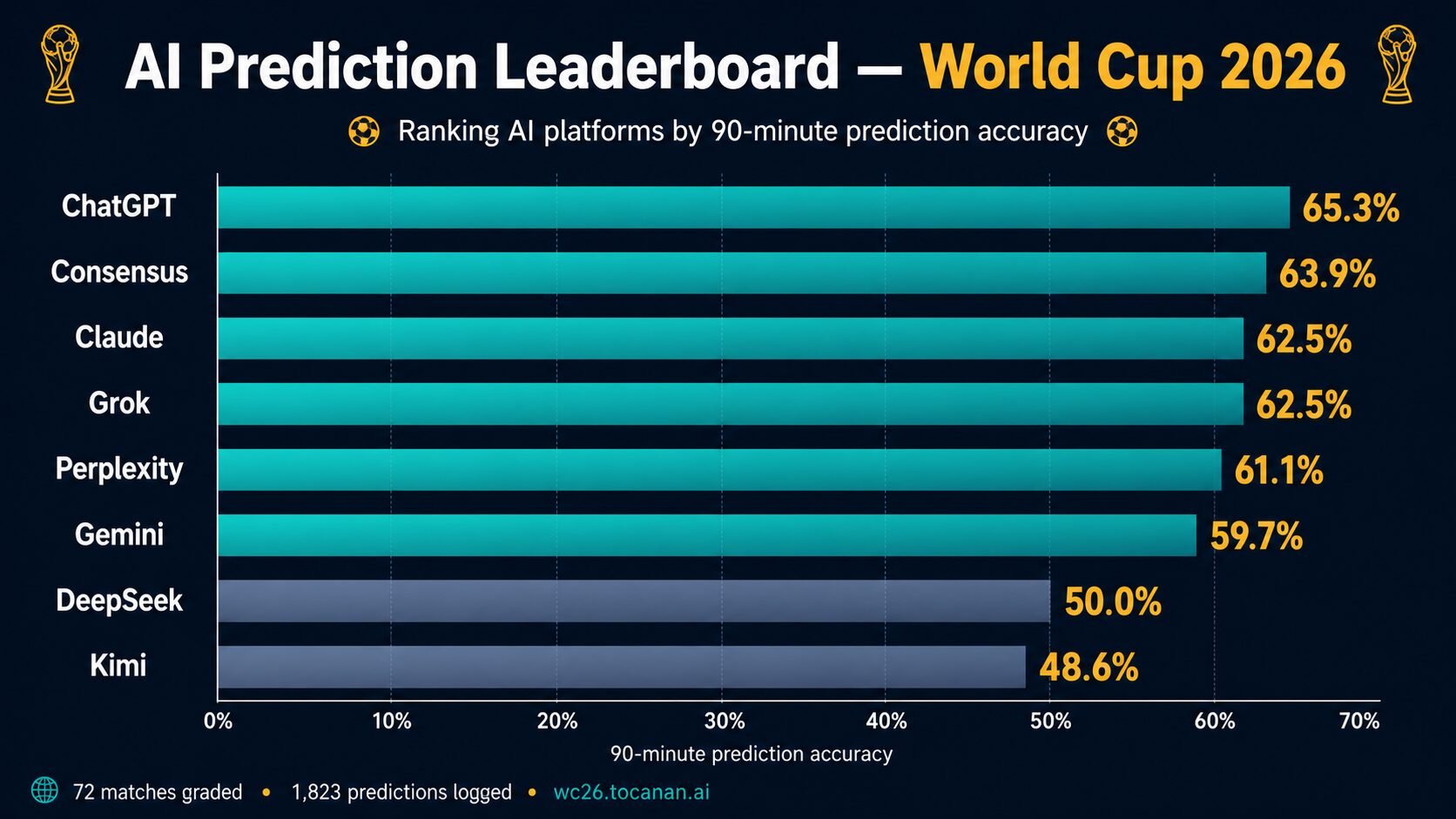
The public leaderboard is already large enough to show meaningful behavioural differences. The WC2026 AI prediction experiment has logged 1,823 predictions across seven AI platforms, with 72 matches graded and no retrospective adjustments.
| Platform | 90-minute accuracy | Record |
|---|---|---|
| ChatGPT | 65.3% | 47/72 |
| Consensus | 63.9% | 46/72 |
| Claude | 62.5% | 45/72 |
| Grok | 62.5% | 45/72 |
| Perplexity | 61.1% | 44/72 |
| Gemini | 59.7% | 43/72 |
| DeepSeek | 50.0% | 36/72 |
| Kimi | 48.6% | 35/72 |
ChatGPT currently leads the 90-minute leaderboard at 65.3% accuracy, while the consensus engine sits near the top at 63.9%.
The consensus result is important. Aggregating platforms beats most single models. Too many companies still ask one model one question and treat the answer as market truth.
Why This Is Really About GEO
Football is the safe public proxy. The real product is measuring how AI systems judge, describe and recommend the world. The same discipline applies to brands:
- Standardise the question.
- Score the answer.
- Decompose the reasoning.
- Compare across platforms.
- Track change over time.
That is Generative Engine Optimization in practice. Not keyword stuffing for chatbots. Not speculative prompt tricks. Measurement first, optimisation second.
If I can score how AI judges the World Cup, I can score how AI judges your brand.
For Tocanan.ai, this experiment is public proof of the measurement layer: timestamped prompts, structured outputs, cross-platform comparison and reality-based scoring. It also shows why visibility without mechanism is not enough. A brand needs to know whether it appears, how it is framed, what evidence is used, where competitors are favoured, and which platform behaviours are stable enough to optimise against. The same measurement layer also exposes GEO poisoning risks when bad source material distorts AI brand recommendations.
AI is becoming the primary discovery and decision layer. Buyers are using generative engines to shortlist vendors, explain categories, compare options and decide who deserves attention. Brands that are not measured and optimised for that layer will not simply rank lower. They will become invisible where decisions are formed.
That is why I keep iterating the football experiment in public. Iteration in public creates credibility no competitor can fake. Every version leaves a trail: what failed, what improved, what changed in the data, and what still needs to be tested.
Reality is still the hardest benchmark in AI.
FAQ
What is this AI prediction experiment?
It is a public World Cup 2026 testbed where Tocanan.ai asks seven AI platforms to predict matches before kickoff, then scores the answers against real results.
How is accuracy scored?
The current leaderboard reports 90-minute match-result accuracy across 72 graded matches. Predictions are locked before kickoff and never adjusted retrospectively.
What does this have to do with GEO?
GEO needs the same method: standardised prompts, structured answers, platform comparison, reasoning analysis and scoring over time. Football provides a public, low-risk proxy for testing that measurement discipline.
Which AI was most accurate?
ChatGPT currently leads the 90-minute leaderboard at 65.3% accuracy, with the consensus engine close behind at 63.9%.