大部分 AI 預測內容,其實都很像表演。
它可能是一張事後截圖、一個聰明的 prompt、一句很戲劇性的判斷,或者把單一答案當成證據。很少有公開時間戳、清楚評分方法,亦很少在現實結果出現後仍然承擔責任。我想做相反的事。
在 World Cup 2026,我建立了一個公開 AI 預測實驗:wc26.tocanan.ai。每一場賽事預測都會在開賽前公開發布,賽後按實際結果評分,之後不再修改。同一條問題會同時問 ChatGPT、Claude、Gemini、Grok、Perplexity、DeepSeek 和 Kimi。
做到第四個版本,這個實驗已經不只是一個足球項目。它變成一個即時示範:我認為 AI 判斷應該如何被測量、改善和商業化。這亦是它和 GEO(生成引擎優化 / Generative Engine Optimization)有關的原因。

四個版本的實驗
AI 判斷只有在問題、答案和評分框架足夠嚴謹時,才真正變得可見、可比較。這聽起來很基本,但實際上,這正是大部分 AI 評估最容易失效的地方。
V1:測量需要標準化
V1 是刻意粗糙的版本。模型可以自由回答。它們用不同方式解釋自己,信心水平不同,有時甚至把結論藏在一大段文字入面。內容本身很有趣,但測量非常脆弱。
當時的教訓很簡單:測量基建必須先於洞察。如果輸出沒有標準化,可比性就會崩潰。你得到的是一堆意見,而不是一個 leaderboard。
對 GEO 來說,這點立即相關。一個品牌不能一邊用不同 prompt、不同答案格式、不同評分規則去測試每個平台,一邊認真問:「我們在 AI 入面有幾可見?」
V2:模型性格開始浮現
V2 強制所有模型使用同一種預測格式。這令答案可以評分,也揭示了更有趣的東西:分佈偏差。
同一條問題,在不同模型之間可以產生很不同的預設姿態。有些模型很果斷,有些會保守。有些過度偏向和局,有些幾乎避免預測和局。
在賽事預測中,Kimi 的和局比例是 32.5%,而 Claude 只有 2.4%。同一任務之下,兩者相差大約 13 倍。這種平台差異,亦正是中國 AI 平台需要獨立測量的原因。
這不是小小的風格差異,而是可測量的模型性格。果斷可以有用,但亦可能掩蓋薄弱推理。審慎可以平衡,但過度避險會削弱可行動性。V2 令一件事變得很清楚:你不應該把「AI 的答案」視為單一事物。
V3:情境會改變數據
2026 年 6 月 21 日,我部署了 V3 cutover。我在 prompt 和 parser 加入結構化概率和風險欄位,令系統由單純 verdict 走向較校準的推理。
cutover 之後,728 條預測帶有明確概率分佈,546 條帶有明確風險欄位。這些欄位在 V3 之前並不存在。
更好的情境改善了測試,但沒有抹走模型性格。V3 令我們不只問「模型選了甚麼」,也可以問:
- 它有多大信心?
- 它有否識別和局風險?
- 它的概率分佈是否支持自己的結論?
這就是概率分數和可行動情報之間的分別。放在 GEO 語境,這亦是「知道品牌有否出現」和「知道模型為何這樣呈現品牌」之間的分別。
V4:目的地與路徑
V4 是現在正在運行的下一步。核心問題是:模型是否能夠分清目的地和路徑?
目的地是最終答案:誰晉級、誰勝出、模型認為會發生甚麼。路徑則是事情如何發生:90 分鐘內取勝、法定時間打和、加時、互射十二碼,或者最後階段的逆轉。
其中一場比賽很清楚展示了這個價值。七個模型全部同意同一個勝方,但對路徑有分歧。五個模型預測法定時間打和,意味著加時或十二碼;ChatGPT 和 Perplexity 則預測 90 分鐘內分勝負。同一個 verdict,不同的緊張位解讀。
我暫時不會聲稱 V4 已經帶來可量化的準確度提升。淘汰賽 leaderboard 要等淘汰賽結果出現後才會填入數據;V4 對 V3 的準確度差異,也只會在數據存在時才納入。這個實驗之所以成立,正正因為規則不會在事後被改寫。
我現在可以說的是質性觀察:V4 令情報更可拆解。它把「會發生甚麼」和「如何發生」分開。AI 輸出就是在這個位置開始變得有用。
數字說明
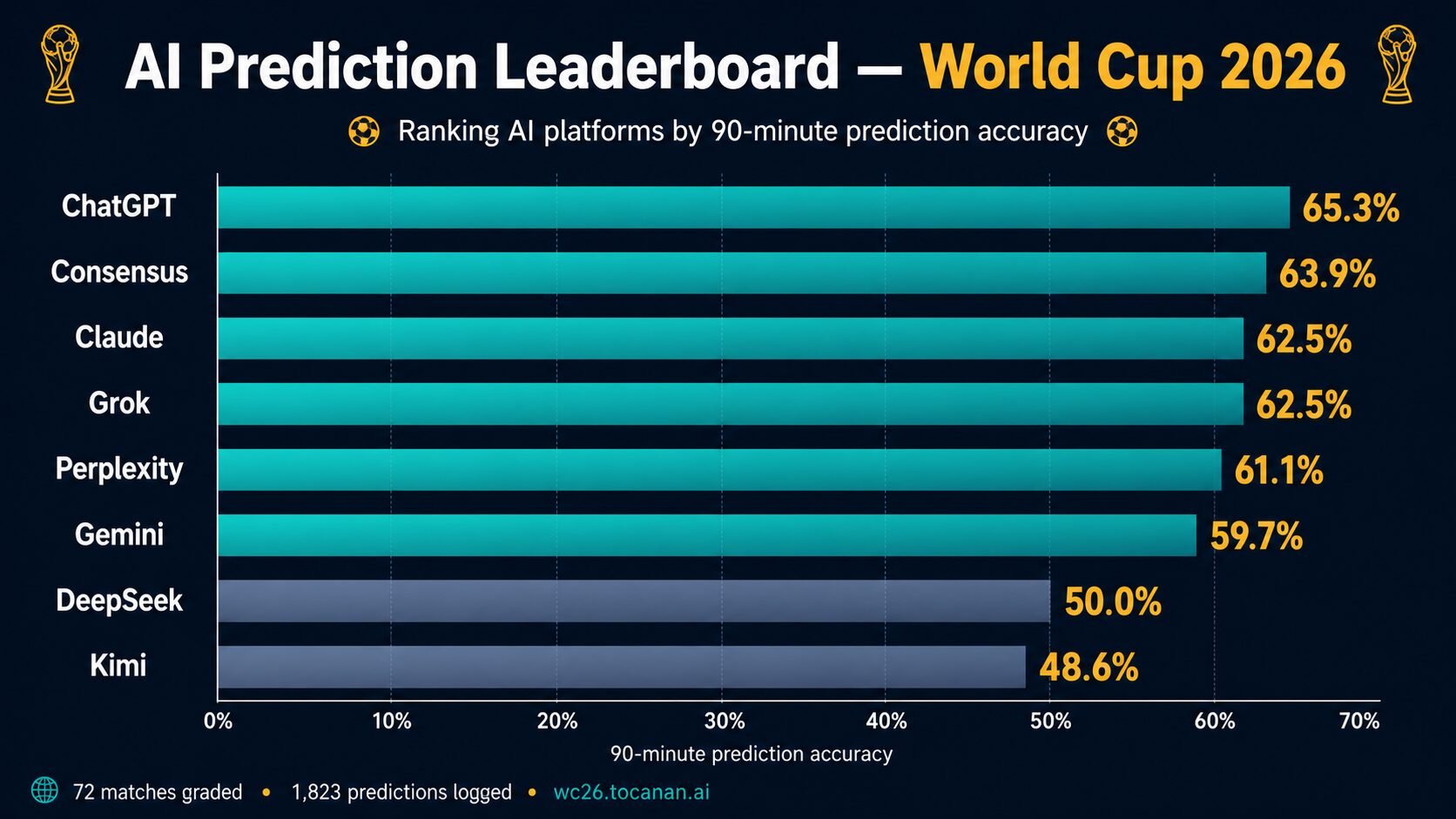
公開 leaderboard 已經大到足以顯示有意義的行為差異。WC2026 AI 預測實驗已記錄 1,823 條預測,橫跨七個 AI 平台;其中 72 場賽事已完成評分,沒有任何事後調整。
| 平台 | 90 分鐘準確率 | 戰績 |
|---|---|---|
| ChatGPT | 65.3% | 47/72 |
| Consensus | 63.9% | 46/72 |
| Claude | 62.5% | 45/72 |
| Grok | 62.5% | 45/72 |
| Perplexity | 61.1% | 44/72 |
| Gemini | 59.7% | 43/72 |
| DeepSeek | 50.0% | 36/72 |
| Kimi | 48.6% | 35/72 |
ChatGPT 目前以 65.3% 準確率領先 90 分鐘 leaderboard,而 consensus engine 亦以 63.9% 接近榜首。
Consensus 的結果很重要。把多個平台聚合起來,表現勝過大部分單一模型。太多公司仍然只問一個模型一條問題,然後把答案當成市場真相。
為甚麼這其實是 GEO
足球是一個安全的公開 proxy。真正的產品,是測量 AI 系統如何判斷、描述和推薦這個世界。同一套紀律可以應用在品牌上:
- 標準化問題。
- 評分答案。
- 拆解推理。
- 跨平台比較。
- 長期追蹤變化。
這就是 GEO 的實踐。不是為 chatbot 做 keyword stuffing,不是投機式 prompt trick,而是先測量,再優化。
如果我可以評分 AI 如何判斷 World Cup,我就可以評分 AI 如何判斷你的品牌。
對 Tocanan.ai 來說,這個實驗是公開證明我們的測量層:有時間戳的 prompt、結構化輸出、跨平台比較,以及按現實結果評分。它亦說明了為甚麼「可見」本身並不足夠。品牌需要知道自己有否出現、如何被框定、模型使用了甚麼證據、競爭對手在哪些位置被偏好,以及哪些平台行為穩定到值得優化。同一套測量層亦能揭示 GEO 中毒風險,即錯誤來源如何扭曲 AI 品牌推薦。
AI 正在成為主要的 discovery 和 decision layer。買家正在用 generative engines 篩選供應商、理解品類、比較選項,並決定誰值得留意。沒有為這一層被測量和優化的品牌,不只是排名較低,而是在決策形成的位置變得不可見。
這就是我持續公開迭代這個足球實驗的原因。公開迭代會建立競爭對手無法偽造的可信度。每個版本都留下痕跡:甚麼失敗了、甚麼改善了、數據有甚麼變化,以及還有甚麼需要測試。
現實仍然是 AI 最難的 benchmark。
FAQ
這個 AI 預測實驗是甚麼?
這是一個公開 World Cup 2026 testbed。Tocanan.ai 會在開賽前要求七個 AI 平台預測賽事,然後按真實賽果評分。
準確率如何評分?
目前 leaderboard 報告的是 72 場已評分賽事的 90 分鐘賽果準確率。所有預測都在開賽前鎖定,之後不會回頭修改。
這和 GEO 有甚麼關係?
GEO 需要同一套方法:標準化 prompt、結構化答案、平台比較、推理分析,以及長期評分。足球提供了一個公開而低風險的 proxy,用來測試這套測量紀律。
哪個 AI 最準?
ChatGPT 目前以 65.3% 準確率領先 90 分鐘 leaderboard,consensus engine 則以 63.9% 緊隨其後。